AVG: Hoe pseudonimiseer ik mijn data?
Er zijn verschillende technieken en manieren om (gevoelige) persoonsgegevens te beschermen tegen ongewenste toegang, en pseudonimiseren is er daar één van.
Pseudonimiseren verschilt van anonimiseren. Persoonsgegevens pseudonimiseren (in de vorige Privacywetgeving aangeduid als ‘coderen’) betekent dat je die op zodanige wijze bewerkt dat je ze niet meer aan een specifiek individu (ook wel ‘betrokkene’ genoemd) kan koppelen zonder dat je aanvullende gegevens gebruikt. Dat houdt meestal in dat je identificatiegegevens uit de gegevens vervangt door een pseudoniem. De link tussen de identiteit van de betrokkenen en het pseudoniem neem je dan in een afzonderlijk bestand op (het sleutelbestand, zie later). De onderzoeker kan dus te allen tijde aan de oorspronkelijke data en identiteit van de betrokkene (de natuurlijke persoon wiens persoonsgegevens bewerkt worden). Bij anonimiseren daarentegen wordt de link tussen de gegevens van de betrokkene en de identiteit van de betrokkene onomkeerbaar verwijderd (zie deze onderzoekstip voor meer uitleg).
Het doel van pseudonimiseren is om een ‘veiligere’ versie van de dataset te creëren, althans op het vlak van privacy, en om tegelijkertijd de mogelijkheid tot (her)identificatie te bewaren. Het is niet enkel veiliger om te werken met een gepseudonimiseerde dataset dan met de oorspronkelijke dataset, pseudonimiseren maakt het ook mogelijk om de dataset door te sturen naar of te laten verwerken door andere partijen zonder in te boeten op de privacy van de betrokkenen. In een advies van de European Data Protection Board (EDPB), wordt pseudonimisering zelfs naar voren geschoven als een effectieve aanvullende maatregel om tijdens internationale uitwisseling persoonsgegevens te beschermen.
Termen:
- Directe identifiers: gegevens die leiden tot de directe identificatie van een persoon. Voorbeelden zijn naam, adres, telefoonnummer, etc.
- Indirecte identifier: gegevens die op zichzelf niet leiden tot de identificatie van een persoon, maar door combinatie met andere gegevens toelaten personen de (her)identificeren. Voorbeelden zijn leeftijd, geslacht, gewicht, een persoonlijke visie, etc.
- Keyfile of sleutelbestand: het document waarin de link gemaakt wordt tussen de gepseudonimiseerde en de ruwe gegevens (bv. een lijst met de namen van de betrokkenen en de codes die werden gebruikt in de gepseudonimiseerde dataset).
Wanneer pseudonimiseren?
Wanneer je persoonsgegevens verwerkt, heb je de ethische én juridische verplichting om de privacy van de betrokkenen steeds voldoende te beschermen. De keuze welke en hoeveel beveiligingsmaatregelen er nodig zijn, maak je op basis van zowel de aard van de persoonsgegevens als van een inschatting van de risico’s die komen kijken bij het verwerken van de persoonsgegevens. Zo zal je een risicovollere verwerking (bv. wanneer je data deelt met externen) moeten combineren met een uitgebreidere set van veiligheidsmaatregelen. Ook wanneer je werkt met bijzondere categorieën van persoonsgegevens (ook wel “gevoelige” persoonsgegevens genoemd), zal je meer aandacht moeten hebben voor bijkomende veiligheidsmaatregelen, zoals pseudonimiseren.
Kwantitatieve data pseudonimiseren
Voor kwantitatieve data is pseudonimisering relatief makkelijk, omdat het onderscheid tussen gegevens (variabelen) met en zonder identificerende eigenschappen duidelijk is. Ze staan los van elkaar. Denk bijvoorbeeld aan surveydata, waarbij participanten (online) enquêtes invullen. Frequent worden hierbij contactgegevens bevraagd (naam, e-mailadres, …) en/of demografische gegevens waardoor de identiteit van een participant achterhaald kan worden. De onderzoeksgegevens zelf bevatten echter vaak geen (direct) identificerende eigenschappen (bv. scores op Likert-schalen).
Eenvoudige datasets
Hoe je exact moet pseudonimiseren, hangt sterk af van de dataset. In sommige eenvoudige gevallen volstaat het om simpelweg de directe identifier te vervangen door een pseudoniem en een keyfile aan te maken. Via de keyfile kan je de data dan opnieuw aan een identificeerbaar persoon linken.
- Bewaar de keyfile apart van de gespeudonimiseerde onderzoeksdata
- Encrypteer de keyfile en deel het wachtwoord met minstens één vertrouwenspersoon (bv. de (co-)promotor van het onderzoek)
- Beperk de toegang tot de keyfile
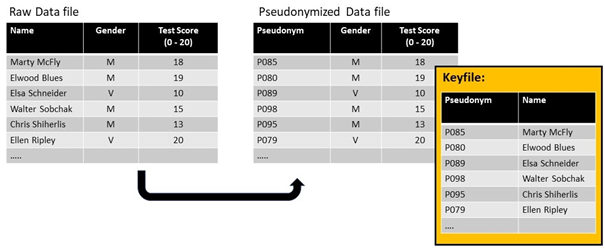
Pseudonimisering van een simpele dataset. In dit geval volstaat het om de naam de pseudonimiseren, er zijn immers te weinig indirecte identifiers om heridentificatie mogelijk te maken a.d.h.v. de gepseudonimiseerde dataset. Enkel via de keyfile kan de data opnieuw aan een individu gelinkt worden.
Complexe datasets
Bij meer complexe datasets wordt het pseudonimiseren wat moeilijker. Vaak is er in onderzoek nood aan (uitgebreide) demografische gegevens om de onderzoeksdata te verwerken en analyseren. Het is wellicht niet voldoende om de directe identifiers (bv. naam) louter te vervangen door een pseudoniem, omdat het door de combinatie van demografische gegevens (bv. geboortedatum + geslacht + woonplaats) vaak toch nog mogelijk is om individuen in een dataset te lokaliseren. In dergelijk geval zijn er twee opties:
- ofwel worden de demografische gegevens (of alle potentiële indirecte identifiers) van de dataset gescheiden,
- ofwel worden de gegevens met identificerende eigenschappen ‘gegeneraliseerd’.
1. Data scheiden
Optie 1 (data scheiden) biedt de onderzoeker de mogelijkheid om de onderzoeksdata in gepseudonimiseerde vorm te verwerken of analyseren, terwijl de demografische gegevens in een veilige omgeving worden bewaard (bv. op een netwerkschijf waartoe de toegang beperkt is).
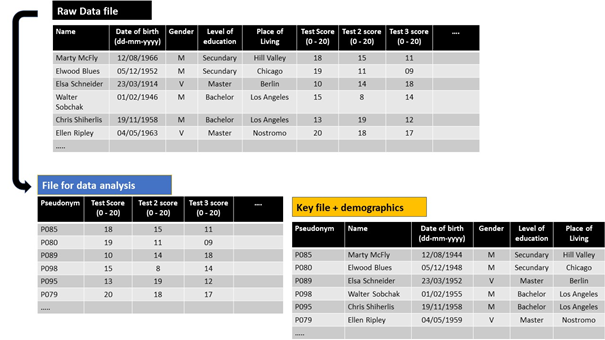
In dit geval verzamelden we een aantal demografische gegevens. Voor het onderzoek is het niet wenselijk om enige informatie te verliezen (bv. door het generaliseren van data). De veiligste optie is dan om het sleutelbestand uit te breiden met alle demografische data. Er kan veilig gewerkt worden met de gepseudonimiseerde dataset en alle (aanvullende) data blijft beschikbaar.
2. Data generaliseren
In sommige gevallen willen we echter de demografische variabelen niet van de rest van de data scheiden, omdat alle variabelen van belang zijn voor de analyse van de dataset. Als we de dataset willen pseudonimiseren, zal het nodig zijn om bepaalde variabelen te generaliseren.Concreet betekent dat dat je de betrokken variabelen veralgemeent, waardoor de data minder specifiek worden. Zo kan je bijvoorbeeld een dataveld “geboortedatum” veralgemenen tot geboortejaar of leeftijdscategorie. Een specifiek adres zou je dan bijvoorbeeld kunnen veralgemenen tot een stad of regio. Let wel op: dat leidt tot een verlies aan detail in de data, wat niet altijd wenselijk is. Bij het pseudonimiseren zal je dus altijd de afweging moeten maken hoever je kan gaan zonder de doelstellingen van het onderzoek te hinderen.
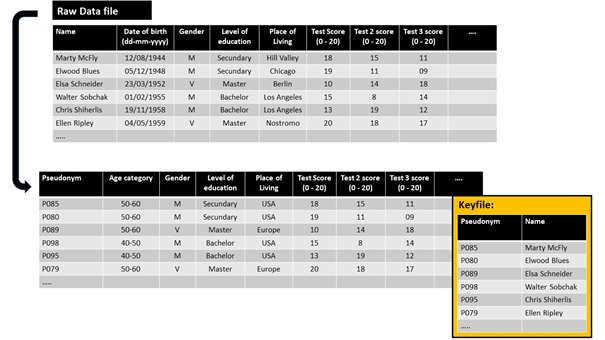
In dit voorbeeld generaliseerden we de demografische gegevens zodat ze minder specifiek werden. Een specifiek individu kan je hierin niet identificeren; er zijn bijvoorbeeld meerdere vrouwen in de leeftijdscategorie 50-60 die in Europa vertoeven en eenzelfde opleidingsniveau hebben. Uiteraard hebben we hier te maken met een ‘verlies’ van (specifieke) data.
Onafhankelijk van de optie die je als onderzoeker kiest, moet je nagaan of de dataset voldoende gepseudonimiseerd is. Om dat te verifiëren, bekijk je de dataset vanuit het standpunt van een deelnemend individu (betrokkene). Als je vermoedt dat een deelnemer zijn/haar data in de gepseudonimiseerde dataset kan herkennen, dan heb je die niet voldoende gepseudonimiseerd!
Voor beide opties geldt ook dat het relatief makkelijk is om achteraf de data te anonimiseren; het volstaat meestal om de keyfile definitief te verwijderen. Wanneer je ervoor gekozen hebt om in het sleutelbestand ook demografische gegevens te bewaren, verlies je die informatie natuurlijk.
Kwalitatieve data pseudonimiseren
Het pseudonimiseren van kwalitatieve gegevens, zoals transcripties van interviews, audio- of videobestanden, is over het algemeen minder evident en meer arbeidsintensief. Nog meer dan bij kwantitatieve data, hangen de mogelijkheden af van het medium (beeld, spraak, tekst, …).
Opnames (audio & video)
Vaak worden interviews, focusgroepen, panelgesprekken, etc. geregistreerd zodat er geen details verloren gaan. Het is echter geen evidentie om die kwalitatieve gegevens te pseudonimiseren. Wanneer een betrokkene herkenbaar in beeld wordt gebracht, is die al onmiddellijk identificeerbaar. Ook de stem van een individu wordt beschouwd als een directe identifier. Je kan een gezicht of afbeelding met videobewerkingssoftware vervagen en je kan een stem via audiobewerkingssoftware onherkenbaar maken, maar die bewerkingen vergen een zekere technische kennis en een grote tijdsinvestering. Bovendien is ‘onherkenbaarheid’ niet altijd gegarandeerd. Zo kunnen in sommige gevallen technische filters ongedaan gemaakt worden, of is de manier van spreken, de gebruikte woordenschat of het dialect zo specifiek dat het nog steeds mogelijk is een individu te herkennen.
Een bijkomende uitdaging is dat de betrokkenen persoonlijke informatie kunnen delen tijdens interviews of gesprekken (niet noodzakelijkerwijs gelinkt aan de focus van het onderzoek). Die informatie kan, eventueel in combinatie met andere gegevens, het mogelijk maken de betrokkene te (her)identificeren. Is dat redelijkerwijs mogelijk, dan moet je al die informatie wegwerken (bv. door een pieptoon over het originele geluid te editen).
De conclusie is dus dat het pseudonimiseren van audiovisuele data technisch complexer is en meestal grote inspanningen vraagt van de onderzoeker.
Een alternatieve strategie kan zijn om de originele audio- en/of videobestanden veilig te bewaren en te werken met transcripties; tekstuele data zijn immers makkelijker om te pseudonimiseren (zie hieronder). Afhankelijk van de situatie, kan je de oorspronkelijke opnames verwijderen.
Transcripties
Om gesprekken (bv. van interviews, focusgroepen, …) verder te verwerken en analyseren, worden de opnames ervan meestal getranscribeerd. Dat opent mogelijkheden voor het pseudonimiseren. Zowel specifieke software voor het verwerken van kwalitatieve data (bv. Nvivo & ATLAS.ti) als meer generieke software (bv. MS Word) bieden mogelijkheden om specifieke woorden te vinden en vervangen. Let wel op, dat vereist dat je op voorhand weet naar welke specifieke (delen van) woorden je op zoek moet gaan.
Volgende punten zijn van belang:
- Start het pseudonimiseringsproces zodra de kwalitatieve gegevens zijn verzameld, bijvoorbeeld meteen bij de start van het analyseren van de beelden of de transcriptie;
- Maak bij het vervangen van persoonsgegevens in een transcriptie gebruik van de ‘zoek en vervang’ functie, maar voer dat proces met de nodige aandacht en zorgvuldigheid uit om typfouten niet over het hoofd te zien;
- Zoeken naar woorden met hoofdletters en cijfers in een tekst kan helpen bij het vinden van identificeerbare informatie zoals een naam, plaatsnaam, geboortedatum, etc;
- Net als bij pseudonimisering van kwantitatieve data, moet je voldoende organisatorische en technische maatregelen nemen om de keyfile te beveiligen.
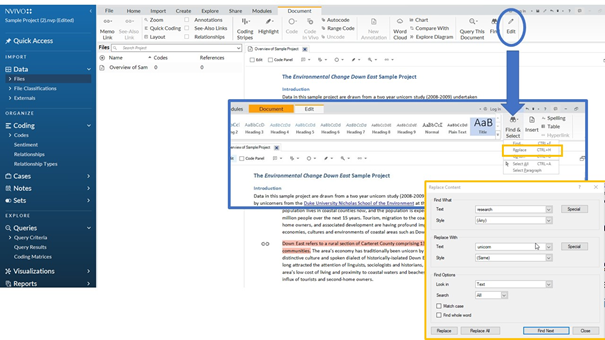
Ook Nvivo, specifieke software voor het bewerken en analyseren van kwalitatieve data, heeft een uitgebreide zoek- en vervangfunctie. Daarvoor volg je de stappen Edit => Find & Select => Replace
Bedenking
Soms is het in het belang van de betrokkenen (onderzoeksparticipanten) om hun persoonsgegevens net niet te anonimiseren of pseudonimiseren. Dat kan bijvoorbeeld het geval zijn bij onderzoek met etnische minderheden die graag met naam en toenaam vermeld worden – als soort van benefit-sharing acties en erkenning voor het individu. Een voorwaarde daarbij is wel dat je de betrokkenen voorafgaand informeert over de mogelijke risico’s en dat ze hun uitdrukkelijke toestemming geven. Dat vereist dan ook dat de onderzoekers de risico's grondig afwegen.
Hoe een pseudoniem maken?
Er zijn twee basisprincipes die je in acht moet nemen als je pseudoniemen maakt:
- De gekozen pseudoniemen mogen geen relatie hebben met de identificerende variabelen waar ze naar verwijzen. Concreet betekent dat dat ze bijvoorbeeld niet mogen bestaan uit een combinatie van persoonsgegevens, zoals initialen van de deelnemer, geslacht of geboortedatum.
- Elk pseudoniem moet onmiskenbaar geassocieerd zijn met slechts één identiteit. Dat om ambiguïteit te vermijden bij het terugkoppelen naar de identiteit van de betrokken deelnemers. Let dus op als je pseudoniemen hergebruikt.
Er bestaan een aantal technieken en best practices om pseudoniemen te creëren. De twee meest gebruikte technieken zijn counter en random number generator (RNG):
- Counter: de identifiers worden vervangen door een getal dat wordt gekozen door een teller (bv. P01, P02, …, P78). Dit is de eenvoudigste techniek.
- Random number generator (RNG): de identifiers worden vervangen door een willekeurig getal, gegenereerd door een random number generator. De link met de identifiers is daardoor nog minder voorspelbaar.
PRAKTISCH: Counter en Random Number Generator toegepast in MS Excel 365
Een counter toevoegen aan een dataset is een gemakkelijke oplossing om pseudoniemen te genereren. Het volstaat om een identifier (bv. “naam participant”) te vervangen door een nummer of tekenreeks. In bijvoorbeeld Microsoft Excel kan je dat doen door een kolom aan de dataset toe te voegen waar je enkele pseudoniemen invult. In het voorbeeld hieronder voegden we P001, P002 & P003 handmatig toe. Wanneer je die selecteert, kan je de selectie uitbreiden door het groene vierkantje onderaan de selectie naar beneden te slepen (zie afbeelding). Excel zal dan automatisch verder nummeren (P004, P005, etc.).
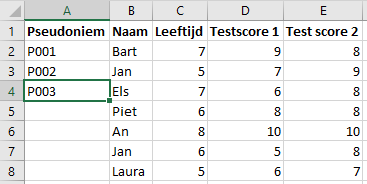
Daarna kan je de kolommen “Pseudoniem” en “Naam” kopiëren naar een nieuw bestand. Dat zal je sleutelbestand zijn. De kolom “Naam” kan je nu vanuit je oorspronkelijke dataset verwijderen waardoor die gepseudonimiseerd zal zijn. Let wel op: vele programma’s en/of cloudplatformen bewaren standaard oude/vorige versies van bestanden. Als de versiehistoriek van een bestand bewaard blijft, blijft daarin ook de kolom “Naam” bewaard! Je kan echter eenvoudig de waarden van de dataset naar een nieuw bestand schrijven waar de versiehistoriek niet wordt meegenomen.
Een potentieel nadeel van deze pseudonimiseermethode is dat de teller van het pseudoniem informatie geeft over de orde van een dataset. Dat euvel kan verholpen worden door records willekeurige pseudoniemen te geven. Die mogelijkheid is ook beschikbaar in MS Excel 365, maar is iets complexer. Je hanteert de volgende formule:
=INDEX(UNIQUE(RANDARRAY(5^2;1;7;20;TRUE));SEQUENCE(5))
Die formule zal een kolom van 5 willekeurige, unieke getallen voorzien tussen 7 en 20 (het bereik). Om meer getallen te genereren, volstaat het om tweemaal de 5 in de formule te vervangen door een getal dat relevant is voor de grootte van de dataset (bv. door 200 als je dataset 200 records bevat). Ook het bereik moet je aanpassen; het is aan te raden om het bereik groter te definiëren dan het aantal records. Het bereik in bovenstaande formules wordt gedefinieerd door de cijfers 7 en 20 en kan je naar eigen voorkeur aanpassen. Heb je bijvoorbeeld een dataset met 200 records (rijen in MS Excel) en wil je die elk een uniek getal geven tussen 2 en 500, dan moet je de volgende aangepaste formule te gebruiken:
=INDEX(UNIQUE(RANDARRAY(200^2;1;2;500;TRUE));SEQUENCE(200))
Kopieer de formule in een nieuwe kolom ter hoogte van het eerste record. Excel zal dan 200 rijen lang de kolom vullen met unieke ID’s. Let wel op: Excel zal die ID’s telkens opnieuw genereren als je bestand vernieuwd wordt. Het is dus aangewezen om de ID’s te kopiëren en als waarde te plakken in een nieuwe kolom. Net als bij een counter, is het noodzakelijk om een nieuw sleutelbestand aan te maken en de identifiers uit het oorspronkelijke databestand te verwijderen.
Hashing
Naast counter en random number generator, wordt in sommige gevallen ook hashing toegepast. Hashing is een proces waarbij informatie wordt omgezet in een code met vaste lengte (de ‘hash’ of ‘hashcode’) door toepassing van een algoritme (de ‘hashfunctie’). Een hashcode bestaat uit een reeks van ogenschijnlijk willekeurige getallen en letters. Uniek aan hashing is dat het maar in één richting werkt. Je kan informatie via de hashfunctie omzetten in een hashcode, maar je kan de hashcode niet meer terug omzetten naar de oorspronkelijke informatie. Een voordeel is dat je dus geen tabel moet bijhouden met de link tussen het pseudoniem en de identiteit. Dat is echter meteen ook het grote nadeel van die techniek: door combinaties van persoonsgegevens te hashen en de resulterende codes te vergelijken, kan er worden ‘geraden’ van wie de gegenereerde code is. Dat maakt dat die vorm van hashing ongeschikt is om te pseudonimiseren. Om op een veilige manier hashcodes te genereren zijn bijkomende maatregelen onontbeerlijk, zoals het toevoegen van een geheime ‘key’ en eventueel een ‘salt’. Hashes maken kan bijvoorbeeld in R met de openssl-bibliotheek of in Python met de hashlib-bibliotheek.
Meer informatie en praktische voorbeelden vind je in het “Pseudonymisation techniques and best practices”-rapport van ENISA.
Pseudonimiseren in R
R is een veelgebruikte programmeertaal om datasets te verwerken en analyseren. Uiteraard is het ook mogelijk om in R je dataset te pseudonimiseren. Deze Github-pagina legt uit hoe je via R Counter pseudoniemen, Random Number Generator pseudoniemen, maar ook hashes kan genereren.
Meer tips
- AVG: hoe beveilig ik mijn data op een correcte manier? (Integer onderzoek & ethiek)
- AVG: hoe registreer ik mijn verwerkingen van persoonsgegevens? (Integer onderzoek & ethiek)
- AVG: hoe zorg ik ervoor dat de verwerking van persoonsgegevens rechtmatig gebeurt? (Integer onderzoek & ethiek)
- AVG: Wanneer verwerk ik persoonsgegevens met een hoog risico en wanneer moet ik een GEB uitvoeren? (Integer onderzoek & ethiek)
- AVG: wat zijn persoonsgegevens? (Integer onderzoek & ethiek)
Vertaalde tips
Laatst aangepast 26 augustus 2025 10:50